Weibo-archiver 存档你的微博 | 开发记录
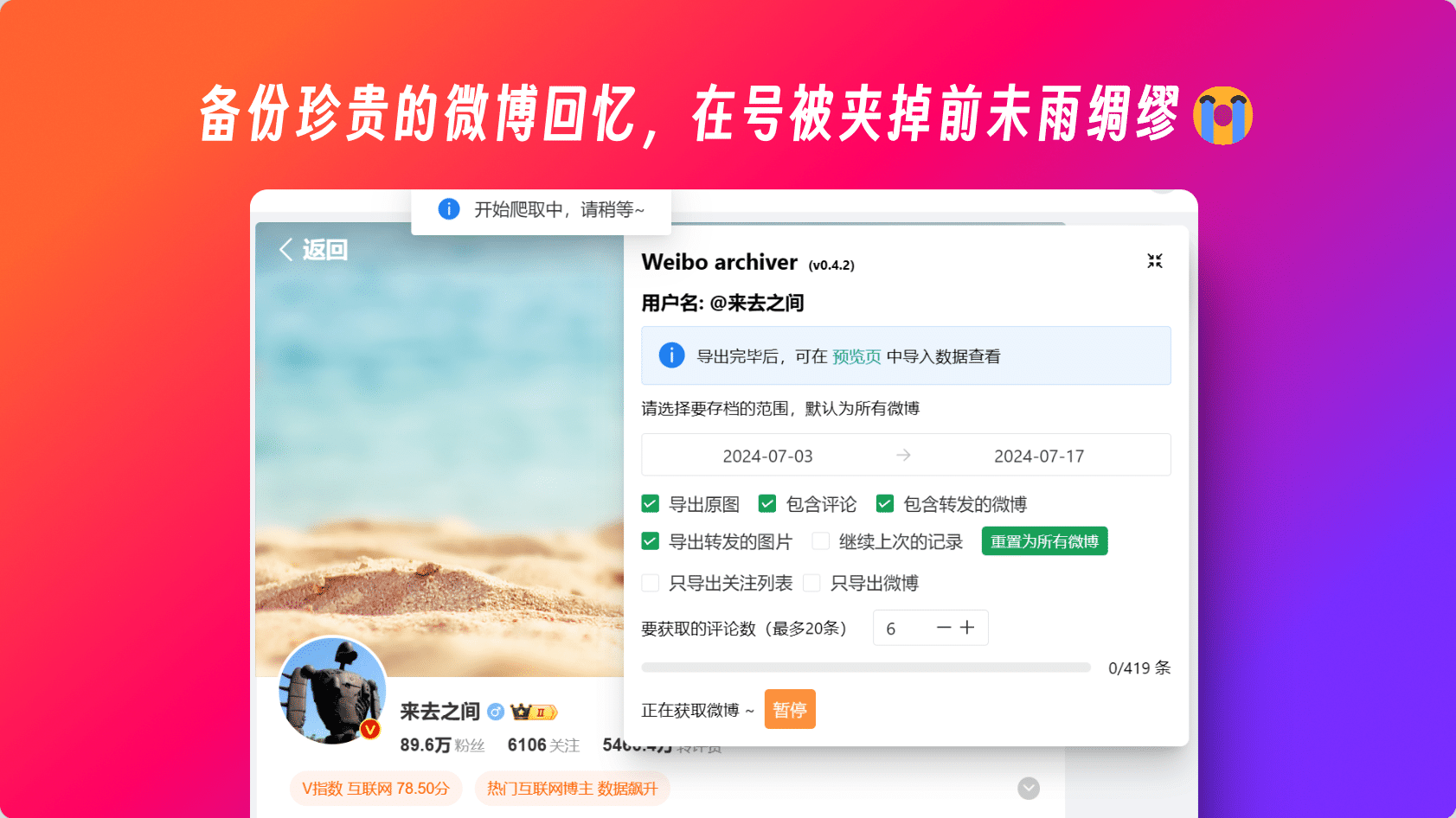
项目地址:archiver
还得自己写一份
之前微博号莫名被夹过一次(事件)后,才意识到是不是该先手备份一份才对,还好只是禁言禁动作,那三千多条微博还是能看。那时翻遍了都没找到几个用得舒服的,特别是我想将它存为 HTML 之类的,图片存到本地,还能做全文搜索、OCR 搜索等等
倒是看到个看着还行的插件,虽然它目的是导出成 PDF,但它是将结果重绘过后重新渲染到本页的 innerHTML 里的,然后再用浏览器的打印来导出 PDF。但这样有很多问题,图片查看不了,毕竟得裁切;最终的 UI 也很简洁;再就是暴力地 innerHTML 的结果就是当数据量特别大的时候,特别他还是一边获取一边插入渲染的,CPU 快被干爆了 hhh
于是当天 fork 后改了改 UI,并将图片全替换成本地的,导出图片链接的数组,再就是手动分页,backup。虽然也还是特别难用,也是能用就行,但手动分页实在是太麻烦了,也不支持按时间范围获取,一直想着什么时候重构一遍
于是就冒出了个想法:用 Vue 来写油猴脚本(后续原作者也用 Vue + Axios 重写了遍)。然后一直拖到了最近才想起来,好在一搜就找到了个 vite 插件 monkey-vite,只要是 vite build 的都能写到油猴中,那这太好了呀
后续写着写着也顺便用 todo 了好久的 monorepo 结构、element-plus、前端分页等等。发了稳定版的 Release,后续应该不大想加新功能了,自用已经够用太多了
开始
写到中间时才又再次想到,又忘记先完整规划再下手......到后面就是边磨蹭边改,然后突然想明白再推翻重做 😅😅
脚本在个人主页运行,于是就匹配 /u/:uid 和 /n/:name这两个路径,但一开始非常蠢地想都没想就用启动模板的 vite-plugin-pages 文件即路由 来创建了个 /pages/u/[id] 的文件)虽然也能跑是吧,然后觉得有些麻烦就用了 vue-router 来匹配 id。到这一步都还是处于能跑的状态,但直到 build 了才发现 router-view 就是不显示。这时候才拍脑袋想到,用 document.URL.match 是不是更简单一些......
再就是一个比较糟的 DX,vite 的热重载是用 ws 来保持连接的,但配合上 monkey 的插件之后在火狐中就连接成了 wss,导致证书问题和 404 而连不上......只好到 edge 来开发)后来想到可能是因为我是在 https://weibo.com 这个 host 下运行的,被 vite 判断成 importMetaUrl.protocol === 'https:' ? 'wss' : 'ws' 了 wss。但很玄学的是只有火狐是这样的,edge 连的还是 ws......到头来就是开了好几个 Chromium,15G 小内存被吃爆了好几次
可能是要延续做法(懒得再动脑),也要一个预览按钮。于是当时的做法是渲染 VNode,然后清空微博 Vue #app 的 innerHTML,再 appendChild 进去。还想着分页,用 pinia 维护了当前页和微博数组,但蠢的是,虽然每次的翻页都是对应地改变当前页就行,但我的做法居然是又再调用 渲染插入 那一套......后来遇到 bug 时才想到这样做直接丢失了先前的状态,而由于翻页的同时又改了 pinia 的当前页,所以一直感觉良好。但菜后知后觉地想到当前页的数组已经是 computed(() => postStore.get()) 了,所以只要改了 pinia 里的当前页就能响应地改过来 hhh
数据获取部分,偷懒就用了 vueuse 的 useFetch,设好 createFetch 的 baseUrl 就行(后来再想,应该设置 base 为 /ajax 而不是 https://weibo.com/ajax,这样 localhost 跨域的时候至少还能设置代理之类的)
最难受的部分之一就是数据清洗......先写好想要的类型,然后就是从返回的 json 捡垃圾了。但历史遗留的问题吧,微博的接口实在是太混乱了 hhh,同个东西换个地方就换字段名了、同一个接口里的字段有不同的名称写法,驼峰和下划线混用就算了,复数的 s 有时在前有时在后 hhh。反正到最后这个 parser 写了快两百行,才算是写了个能用的
图片预览
其中,图片防盗链的问题,b 站(转发卡片的图片)和微博的策略不同,只好在油猴预览时就按原链接用 weibo 的 referer,本地预览就换为 /assets/img 这样的本地图片(但存在数据里的还是原图链接)。插曲是,为了能够解析带图转发的图片,想法是将它转换为自定义协议 [img://${src}],而后显示的时候再解析成一个 <button data-src="${path}">查看图片</button>
const retweetImg = /<a[^>]*href="([^"]*)"[^>]*>查看图片<\/a>/gm.exec(text)
if (retweetImg && retweetImg[1]) {
const img = retweetImg[1]
text = text.replace(retweetImg[0], `[img://${img}]`)
}
这样就需要一个全局的图片预览器,这里用了一个 比较取巧的方式来实现。在 <Text/> 组件中,先获取所有文本中的 button(只有这种行内图片才用 button,当然也能换成别的选择器)
const parsedText = parseProtocol(props.text)
// 或许不该这么写......
onMounted(async () => {
const btns = await waitForElement('button')
btns?.forEach((e) => {
e.onclick = (_) => {
const url = e.dataset.src
if (url)
usePostStore().viewImg = url
}
})
})
用 pinia 来存要预览的图片链接。然后这个 viewer 就 watch 它,借用 el-image 的相册预览功能,有变化时就自动点击预览它
<script setup lang="ts">
const postStore = usePostStore()
watch(
() => postStore.viewImg,
async () => {
if (postStore.viewImg === imgViewSrc)
return
const img = await waitForElement<HTMLImageElement>('#img-viewer img')
img?.[0]?.click()
},
)
</script>
<template>
<div id="img-viewer" class="absolute right-0 top-0">
<el-image
class="h-0 w-0"
:src="replaceImg(postStore.viewImg)"
:lazy="true"
:hide-on-click-modal="true"
:preview-teleported="true"
:preview-src-list="[postStore.viewImg]"
@close="() => (postStore.viewImg = imgViewSrc)"
/>
</div>
</template>
其中,默认情况下是用一个 1x1 的透明占位图,以免图片 404 后 el-image 的 img 标签就变成了 <p>Failed</p>
export const imgViewSrc
= 'data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7'
糟糕的开始——数据导出
快收工时又才发现没考虑一个问题:数据导出?
导出了清洗后的微博.json 和图片链接.csv,但本地预览的 HTML 怎么办捏。因为都是 vue,肯定得先编译才会有生产版本的 HTML 嘛,但脑瓜不精灵总想着在浏览器中完成(也就是在 build 中再 build 另一份 vue hhh)。睡醒后才又拍脑瓜,只要手动 build 出预览的部分,然后一同打包到 Release 里就好了嘛
同时又遇到个难题,在预览中是要导入用户数据的,也就是最后打包的时候要让这部分与 index 分离(因为 vite 的打包都是 Bundle 到一个文件里的),这时候就要手动配置 vite build 的逻辑了
首先将 pinia 的 posts 不设为默认的空数组,而是导入另起的文件 data.js
import _posts from '../static/data.js' // 后来显式地改为了 data.mjs
// in defineStore
// 必须是外部导入优先, 这样才能在 build 中直接引用
const posts = ref(
(_posts as unknown as Post[]).sort((a, b) => Number(b.id) - Number(a.id)), // 按 id 也就是发布时间降序排列
)
然后在 vite.config.ts 中设置,将 data.js 单独出来,并将 js|css 都打包到 assets 文件夹下,同时要出掉他们的 hash 命名,这样就能直接覆盖源文件了
const dataJs = path_to_data
export default defineConfig({
...config,
build: {
rollupOptions: {
input: {
index: path_to_index_html,
data: dataJs,
},
output: {
entryFileNames: 'assets/[name].mjs',
globals: {
[dataJs]: 'data',
},
},
},
},
})
也就是在这时候,意识到了打包 monkey 和预览的 vue 是冲突的,必须手动注释掉其中一个才能打包另一个......于是想到了 monorepo,将共同的部分抽离到 /core 中,/preview 和 /monkey 分离来开,单独配置
还是在当晚,看了会 pnpm + monorepo 的组成和使用,逐渐理解起来,并顺利迁移了过去 😇
其中,需要单独设置各自的 vite.config,只要 继承 (解构赋值)自共同的根目录的配置就行(像是 vue、UnoCSS 那些的)。以 /monkey 为例:
// /packages/monkey/vite.config.ts
export default defineConfig({
...config,
build: {
outDir: path.resolve(root, 'dist'),
rollupOptions: {
output: {
plugins: [terser()], // 压缩输出,打包直接少一半的体积
},
},
},
plugins: [
...config.plugins!, // 一定要先声明这个,否则就相当于覆盖了根配置的 plugins 数组
monkey({
entry: 'src/main.ts',
userscript: {
name: 'Weibo Archiver',
},
// ... 等等其他配置
}),
],
})
然后在根 package.json 配置 scripts 就好:"dev:preview": "pnpm -F preview dev", "dev:monkey": "pnpm -F monkey dev"
重构完睡醒后就发了第一个能跑的 Release,后续几天就是在完善功能了
全文搜索
想着还是得写一个搜索功能,好找一点。据我的一点点了解,这部分似乎需要先中文分词,然后建立与 id 的索引,于是没多想就这么做了)
但搜出来的包都是需要 node 环境,以及鉴于词库的存在,分词是不会在浏览器完成的,于是需要一个后端
但同时要打包出来,就搜到了 vite-express-plugin 的插件,能跑
就这么写了好一会能出结果了,build 的时候才想到,那依赖怎么办......它要么是打进单文件里,要么是 resolver 出来,但既不提供 package.json ,也不会复制 node_module 过去
因为还真没想过像是 express 的 node 服务要怎么 “打包”,再就是服务端直接 node main.js 就行了,似乎也用不上打包这个动作)一般都是上传代码,然后运行 pnpm i 之类的就行。只有浏览器才需要这么一个“可执行”入口,才要将依赖打包进单文件里
于是苦心研究了下 rollup,最终的结果是手动复制一份非 dev 的依赖的 package.json 进 dist,再手动 npm i 和 node main ......
实在是麻烦......于是又睡醒后拍大脑,不考虑性能什么的,用正则岂不是更快实现......?
async function searchText(p: string): Promise<Post[]> {
const res = posts.value.filter((post) => {
const word = p.toLowerCase().trim().replace(/ /g, '')
const regex = new RegExp(word, 'igm')
return (
regex.test(post.text)
|| (post.card && regex.test(post.card?.title))
|| (post.retweeted_status && regex.test(post.retweeted_status?.text))
)
})
resultPosts.value = res
return res
}
心酸历程:pr/search。写服务期间,还是没想明白 ts-node 与 module 的共存写法,最后还是换成了 js 来写,瞬间舒服极了
添加更多的 fetch 选项
一想到也许有些人的微博有数万条,要是不能筛选就麻烦了,于是就连忙加了一些 options 来给用户选择
还得是用 Vite 来预览结果
在有人反馈之前,我都没意识到之前的 server.py 有着直接打不开的致命问题……尝试了很久,但还是很难解决 serve 一个 vue SPA 的一系列问题。最终还是改为 Vite 来预览了,顺便把下载图片也转一手 Node 版本,最后连同 node_modules 一起打包到 Release 里。这样用户只需要下载 node 就行了
并加了个说明:issues/#5
最后……?
完成搜索后,可以说就完结了,不大再想新增功能,够用就行......改改 bug 就好
实际上并没有hhh
总的来讲,还是学了挺多的,虽然弯路和坑太多了 😅😅
在这之后
最近在自搜的时候发现这个项目被人推荐了:小众软件,还有一百多的转发,瞬间觉得两股战战 hhh)多了好多 stars
吓得立刻改了几个地方,然后才发现导出按钮没反应是因为 jsZip 的新版本与油猴有些冲突了,但在开发环境是没问题了,这只好降级解决了。并添加了几个导出的选项,毕竟他们可能有几万、十几万条微博,不过滤像是转发、评论区等的话,这实在是太不合理了
还有一点,用的人多起来后(恰逢微博准备开始前端实名制,这会有更多的用户有需求存档他们的微博),意识到了一点是,应该降低使用门槛、简化操作,这样才能让更多人能用得上
于是接下来打算打包到 Tauri 上,数据的处理等等全都自动化,用户只要简单地登录、设置、导出就好了。查看结果也可以很简单地直接打开 app 就能加载了,还能很方便地支持多用户
下载图片这部分还能尝试一下 Rust 的加速),用户就不需要额外的环境配置。而且像是分词索引这部分也就能很合理地存在用户电脑上,不用再正则暴力搜索了